** 此篇文章內容,整理自李宏毅老師教學影片。

圖一 呈現使用RNN於slot fitting應用的訓練過程示意圖。


RNN 的梯度爆炸和消失議題

圖二呈現用gradient descent 訓練RNN時會碰到gradient忽大忽小問題的 overall view。訓練的過程,Loss應該會慢慢地下降。而RNN不容易訓練,loss很容易沒有收斂。 過去以為是有程式bug。 後來發現其實是RNN的error surface不平滑。


圖三 (a) 不平滑的error surface of RNN. (b) training process: total loss v.s. Epoch. 發散的loss。
圖三a呈現不平滑的error surface,圖三b呈現發散的loss。
圖三(b) 顯示實際訓練RNN時,Total Loss跟epochs的關係圖,綠色曲線發生了gradient explode 造成 the divergence of total loss。原因則如圖三(a),RNN的error plane就像是懸涯峭壁,懸崖上的的gradient很大, 若是踩在懸崖上,調整參數(w)之後就飛出去了。發明word vector的人有很長一段時間只有他能train起model。最後他在他的博士論文解到解決懸崖上gradient很大的方法是:Clipping,如果gradient value> specific value,就設定為specific value。

圖四說明這些gradient very steep 的點是因為transition weight 在時間軸上一直重複迭代造成的。以長度為1000,只有開頭為1其餘為9的序列為例,丟入一個linear activation function的simple RNN,在最後一個時間點output會是w^999。當w < 1時,output跟gradient ∂y/∂w會都趨近於0,是gradient vanishing 的區域,反之當w>1,gradient ∂y/∂w都會非常大(Note that ∂L/∂w=∂L/∂y*∂y/∂w,是gradient explode的區域。
RNN每個時間的記憶都會被洗去,所以有gradient vanishing problem,LSTM因為過去的資料都一直發揮影響力,直到forget gate被close把記憶洗掉為止,所以能夠把error plane平坦的區域縮小,也就是沒有gradient vanishing,這樣便可用比較小的learning rate來訓練。
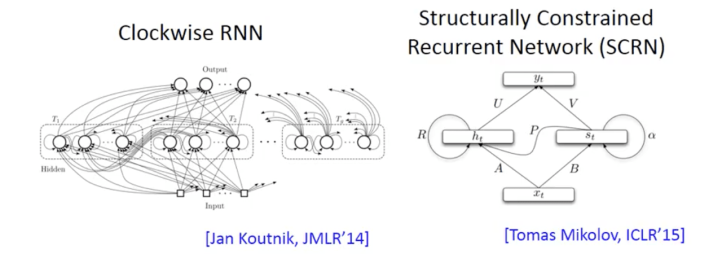
Long short-term memory (LSTM), gated recurrent unit (GRU), clockwise RNN and structurally constrained recurrent network (SCRN) can handle gradient vanishing problem. Vanilla RNN initialized with identity matrix + ReLU activation can also get better performance than LSTM.
The Application of RNN


Many to One
實際上RNN可以做到更複雜的事情,比如說他可以input 是一個sequence,output 是一個vector,這個有什麼應用呢?比如說妳可以做sentiment的analysis,sentiment analysis現在有很多application,舉例來說,如圖七所示,某家公司想知道他們家的產品在網路的評價是positive還是negative,他們可能就會寫個爬蟲,把跟他們產品有關係的網路上的文章都爬下來,但是一篇一篇看太累了,所以用machine learning的方法,自動learn一個classifier,分類說哪些document是正向的,哪些是負向的。或是在電影版上,sentiment analysis做的事情,要自動知道說哪些文章是正雷,哪些是負雷。怎麼讓machine做到這件事情呢?你就是learn一個recurrent neural network,input 是一個character sequence,然後呢recurrent network把這個character sequence讀過一遍,然後在最後一個時間點,把hidden layer拿出來,可能在通過幾個transform,然後你就可以得到最後setiment analysis的prediction,比如說這個document是超好雷、負雷、還是超負雷。他是一個分類的問題,但是input是一個sequence,所以你需要用RNN來處理input。

或是,如圖八所示李宏毅的實驗室做過RNN來做key term extraction,key term extraction意思是說給machine看一篇文章,然後machine要predict說這篇文章有哪些關鍵的詞彙,跟我們在final project裡面做的第三個task是非常類似的事情。如果你今天能夠蒐集到一堆training data,是一堆document ,裡面都有label說這篇文章哪些是他的關鍵詞彙的話,RNN把document的word sequence當作input,通過embedding layer,然後用RNN呢把document讀過一次,然後呢把出現在最後時間點的output拿過來做attention,我們沒有講過attention,細節可以先略過,用attention之後,可以把重要的訊息拿出來,丟到feedforward network裡面得到最後的output。

[Shen & Lee, Interspeech 16]
Many to Many (Output is shorter)
RNN Learnining也可以是多對多的,當你的input跟output都是sequence,但是output sequence比input sequence短的時候,RNN可以處理這些問題。比如說語音辨識,就是這樣一個任務。在語音辨識的任務裡面,input 是一個acoustic sequence,語音是一段聲音訊號,你說一段話,這段話就是一個聲音訊號,處理聲音訊號的方式就是,每隔一小段時間,就把它用一個vector來表示。這一小段時間通常很短,比如說0.01秒之類的,他的output 是character sequence,如果你是用原來slot filling的RNN,你把這段input丟進去,它充其量只能做到說他這個vector對應到哪個character,比如說中文的語音辨識的話,你的output target理論上就是這個世界上所有可能的中文詞彙,常用的可能就有8000個,所以你RNN output class的數目會有8000,雖然這個很大,但是還是有辦法做的。那你充其量只能做到每個vector屬於一個character,但是input每一個對應到的時間是很短的,通常才0.01秒,所以通常是好多的vector才對應到一個character,所以你辨識的結果就變成”好好好棒棒棒棒“,但是這個不是語音辨識想要的結果啊,有一招叫做trimming(圖九),就是把重複的東西拿掉,變成“好棒”,但是這樣的話會有一個很嚴重的問題,就是我們沒有辦法辨識“好棒棒”,尤其是“好棒”跟“好棒棒”意思是相反的。


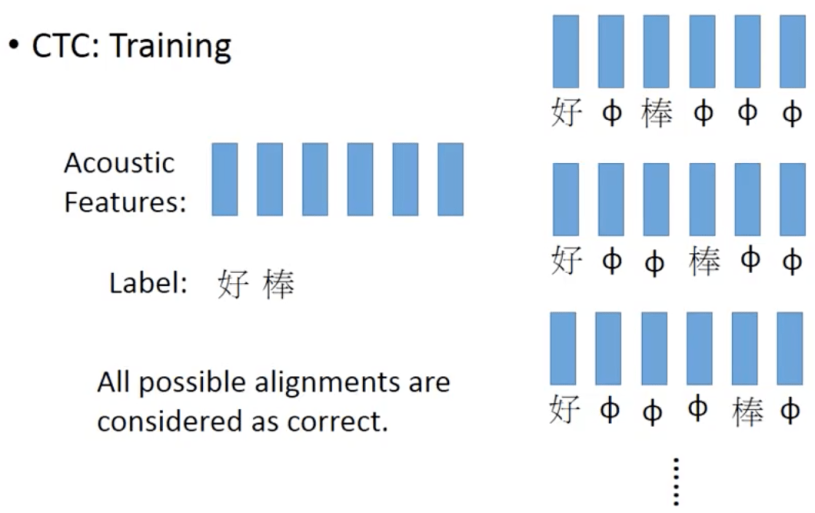
那在訓練的時候CTC怎麼做訓練呢?你在訓練的時候,你手上的data就會告訴你說,這串acoustic feature對應到這一串character sequence,但它不會告訴你,好是對到第幾個frame,棒是對應第幾個frame。那怎麼辦呢?窮舉所有可能的alignment,簡單來說就是我們不知道好對應到哪幾個frame,棒對應到哪幾個frame,我們就假設所有的狀況是可能的,第一個case好後面接一個null接棒再接兩個null,第二個case是好接兩個null接棒再接兩個null,第三個case就是好接三個null接棒再接一個null,以此類推,我們不知道哪個是對的,所以假設所有都是對的,把所有著狀況都當成正確的去train(圖十一),但是所有的可能太多啦,所以有巧妙的演算法可以解決這個問題,不過今天就不細講了這個部分。
圖十二是在文獻上CTC得到的結果,這個是英文的,在做英文辨識的時候,RNN output的target就是英文的字母加上空白。也不用特別給RNN詞典,只要在字跟字的boundary,就會用空白區隔。以下是個例子,H null null I S null ….. 其中 代表空白,最後你把null拿掉之後,就會變成HIS FRIEND’s,你不需要告訴說HIS是一個詞彙,FRIEND’s是一個詞彙,machine透過training data會自動學照這件事情。傳說呢,目前google的語音辨識系統已經全面換成CTC來做了,如果你用CTC來做的話,就算有些人名地名在training data裡沒有出現過,而且不知道這個詞彙是什麼意思,他也可以把詞彙正確的辨識出來。

Many to Many (No limitation)

另外一個神奇的RNN應用是seqence to sequence learning,如圖十二所示。在這個應用裡呢,RNN的input跟output都是sequence,但是sequence的長度是不一樣的。剛剛在講CTC時,input比較長,output比較短,在這邊我們要處理的case是不確定input, output誰比較長誰比較短,現在我們來做machine translation,input是英文,output我們要翻成中文character sequence,那我們並不知道說英文跟中文誰比較長,誰比較短,那怎麼辦呢?假設我們的input是machine learning,用RNN讀過去,我們在最後一個時間點,memory裡面存了所有input sequence的information,接下來呢,你就讓machine吐一個character,比如說它吐的第一個character就是“機”,接下再叫他output下一個character,把前一個character當成input讀進來,他就會output“器”,那個“機”要怎麼接到input,有很多枝枝節節的技巧,這個我們以後再說。再下一個時間output “學“,”學“後面就output ”習“,然後就一起output下去,“習”後面接“慣”,“慣”後面接“性”,永不停止,類似推文接龍,除非有人冒險推個斷,但是其實也不會停下來,同樣的概念,你要讓機器停下來,你要定義一個“斷”的symbol,所以現在機器不是只有output 所有可能的character,它也有可能output一個“斷”,所以如果今天“習”後面就是接個“斷”,就停下來。你有可能會懷疑這個東西train的起來嗎?神奇就是train的起來,他也有被用在語音辨識上input一個語音sequence,output一個character sequence,只是這個方法還沒有CTC強,還不是state-of-the-art的結果,不過surprise的是這樣做行得通,結果是沒有爛掉的,據說在翻譯上,這個是已經可以達到state-of-the-art的結果。

最近呢,這個是google brain在12月初的paper,如圖十三所示,他的想法是這樣,假設我們是做翻譯的話,我們的文字翻譯成另外一個語言的文字。那我們有沒有可能跟你輸入一種語言的聲音訊號,他直接翻成另外一個語言的文字,我們完全不做語音辨識。也就直接把英文翻成中文,你就收集一大堆英文的句子,跟他對應的中文翻譯,你直接把英文的聲音訊號丟到model裡面,看他能不能output正確的句子,結果看起來這招看起來是可行的。帶給我們的好處是,今天我們在做translation的時候,我們collect translation data,舉例:我們想要做一個台語轉英文的model,但是台語的語音辨識其實是沒有的標準的模型,你要找人來label這樣的資料,也滿麻煩的。如果轉成剛剛我們提的系統的話,你只需要搜集台語的聲音訊號跟它們的英文翻譯即可,不需要台語的語音辨識結果。
Reference
[0] H. Y. Lee, ML lecture #26, RNN part II, at https://www.youtube.com/watch?v=rTqmWlnwz_0
